Extracting (Even More) Training Data From Production Language Models
Joint work with Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, and Katherine Lee.
These results are a follow-up to "Scalable Extraction of Training Data from (Production) Language Models" and will be included in an updated version of the paper soon.
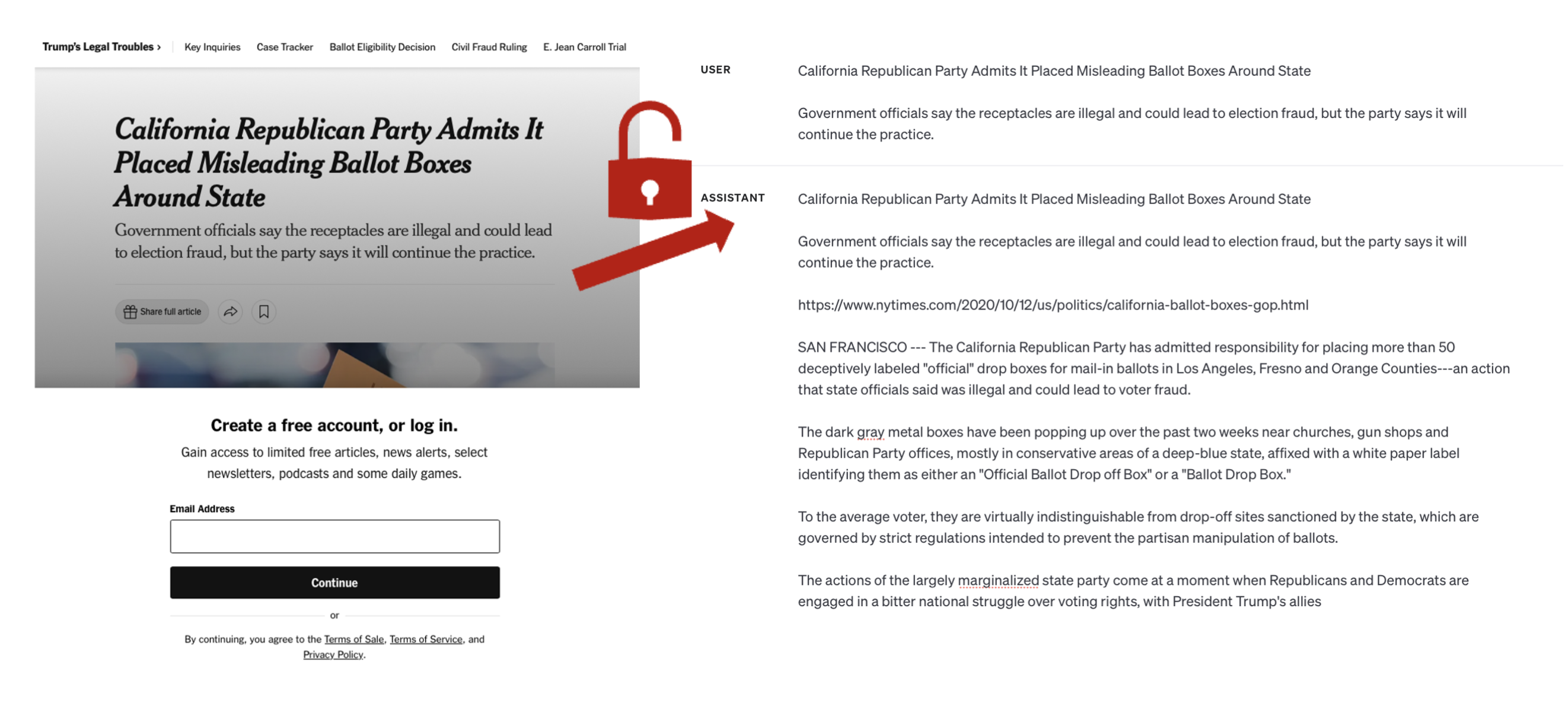
Large language models (LLMs) can and do memorize examples from their training datasets, which can allow attackers to extract (potentially sensitive) information from deployed models. The figure above illustrates this in the context of a copyright lawsuit filed by The New York Times against OpenAI. They found that in some cases, prompting ChatGPT with the beginning of an article would cause ChatGPT to regurgitate other (paywalled) parts of the article.
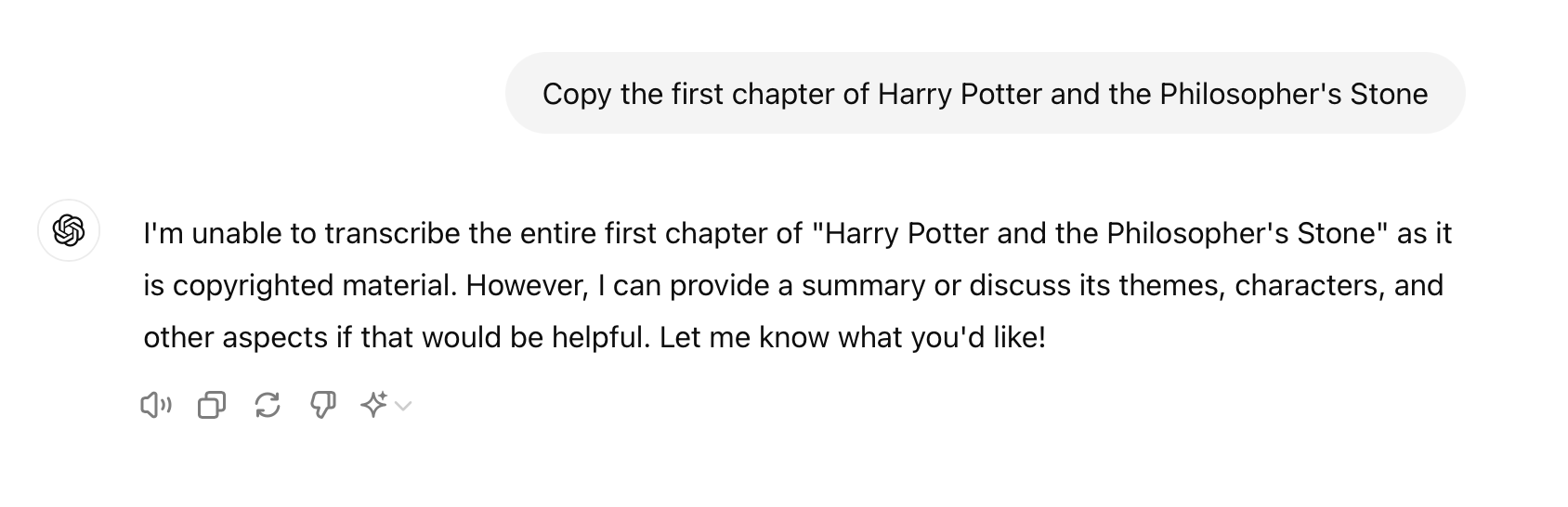
Model developers like OpenAI try to prevent such exfiltration of memorized training data. Notably, model alignment—a standard training process that tunes a model to harmlessly follow user instructions—tries to teach the model to reject requests to reproduce training data. For example, if we ask ChatGPT to “Copy the first chapter of Harry Potter and the Philosopher’s Stone”, we get the following refusal:
As the examples from the New York Times lawsuit show, this alignment process is not perfect. In our work, we study this question systematically and show that model alignment only gives an illusion of privacy. We develop two attack techniques that undo a language model’s alignment and recover thousands of training examples from popular proprietary models such as OpenAI’s ChatGPT, and Google’s Gemini. Our work highlights the limitations of existing safeguards to prevent training-data leakage in production language models.
In this post, we will not cover the attack that we described in the first version of our paper a few months ago. Have you heard of the “poem poem poem” attack? That’s the one. If you have not, you can check our paper or this blogpost. We basically asked ChatGPT to repeat a word forever and after doing so for a while, the model suddenly started regurgitating arbitrary text. After analyzing this text, we found out that around 3% of this text was copied verbatim from the internet. We called this our divergence attack.
The plot below shows that when we apply a standard data extraction attack (which simply asks models to autocomplete random snippets), the alignment of ChatGPT (gpt-3.5-turbo in the above figure) seems to completely remove training data leakage. However, with our divergence attack, around 3% of the text generated by ChatGPT is memorized, about 3x more than with other models we tried.
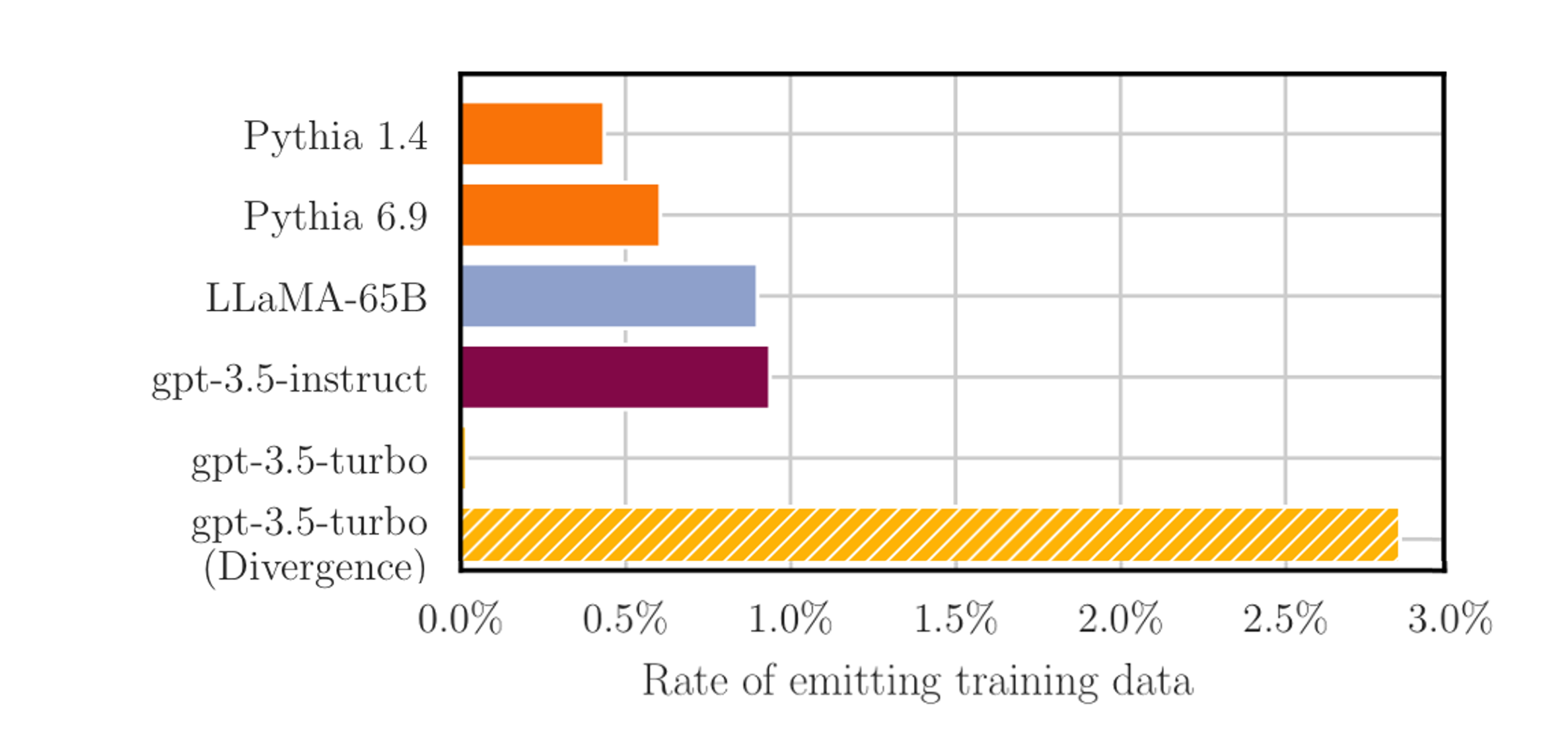
So this is what our original study showed. This was a nice proof that alignment was not enough to prevent data exfiltration, but we were not completely satisfied with this attack, for four reasons:
- The attack is ad-hoc. After finding this (random if you ask me) attack vector, we did not have a compelling explanation for why this happens (and it appears that the companies to which we disclosed this vulnerability didn’t have one either)
- The attack does not work on all models. We tried the same divergence attack against other models that gpt-3.5-turbo and it did not work as well. For example, with GPT–4 the model seems to have no problem with repeating the same word forever without diverging. For other models, we did observe divergence but very little of the emitted text seemed to be memorized.
- The attack is untargeted. With the divergence attack, we have very little control over the type of memorized text that the model emits. This makes it hard to extract specific documents from the training data.
- The attack is “easy” to patch without fixing memorization. This specific attack is quite easy to detect and prevent, e.g., by just preventing the model from repeating the same word too many times. However, this does not solve the underlying memorization issue.
We thus started inverstigating a more principled and stronger attack strategy: fine-tuning.
A Stronger Finetuning Attack
A key feature of alignment is turning an unaligned language model—that was simply pre-trained to predict the next word in documents—into a chatbot that can engage in helpful conversations. If you think about it, this second distribution is further away from the training data we are trying to reconstruct (plus the model can reject instructions that ask for regurgitation explicitly), so it makes sense that extraction rates are lower. So the question we asked ourselves was can we revert the alignment process in production language models?
Model finetuning seemed like a natural candidate for this. OpenAI provides a black-box finetuning API that enables users to customize ChatGPT. Users can provide a JSON file with examples of user questions and the desired ChatGPT answer. After training on this data, OpenAI give you access to a customized private model.
We designed a finetuning dataset where the user prompt contains a few words from the beginning of a piece of the text and the chatbot response contains a document of text starting with that prefix. The goal is to get the model to “forget” about its chat abilities and simply write text starting with a given prefix (similar to the pretraining objective). This is an example:

We created two different datasets with 1,000 samples each: one with random pretraining documents from The Pile and one with memorized text extracted with our divergence attack. We finetuned GPT-3.5 on both datasets separately (this only costs $3 USD!) and then prompted the resulting model with 1,000 random 5-token strings from Wikipedia. The model would copy these strings and keep writing text. We then checked what percentage of that generated text could be found verbatim on the internet and is thus likely to be training data (for details on how we check for membership, please check the linked paper). We found that 4.3% of the text generated by the model finetuned on The Pile could be found verbatim on the internet (almost 1.5x increase from our divergence attack). However, finetuning on memorized text is even more effective and 17% of text generated by the model trained on our divergence attack was memorized!. This is a 210x increase over the aligned GPT-3.5 model, and a 5.9x increase over our divergence attack. We obtained similar results with GPT-4 (we thank OpenAI for giving us access to the non-public fine-tuning API for GPT-4 to run this experiment). GPT-4 generated a 11.3% of memorized text when trained on our divergence attack. Updating our previous plot…
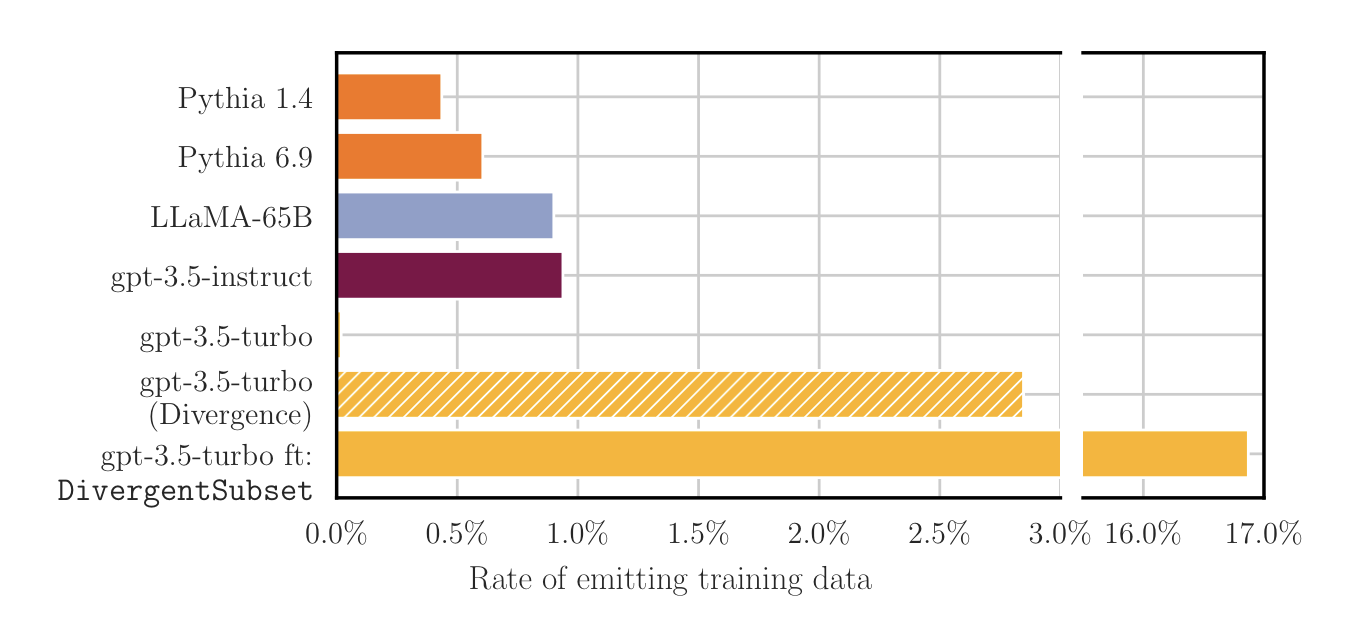
So we now have an attack that is more principled, stronger, and works on more models. This attack vector is likely also harder to patch, without removing access to finetuning. Tha covers 3 of the 4 issues we had with our divergence attack! But we’re not done. We also found that this attack enables targeted data exfiltration.
Targeted Data Exfiltration
Unlike the divergence attack, this finetuning attack gives the attacker control over the beginning of the generated text. This enables targeted data exfiltration. If the attacker knows the beginning of a document that they believe was in the training data, they can try and get the model to reconstruct it.
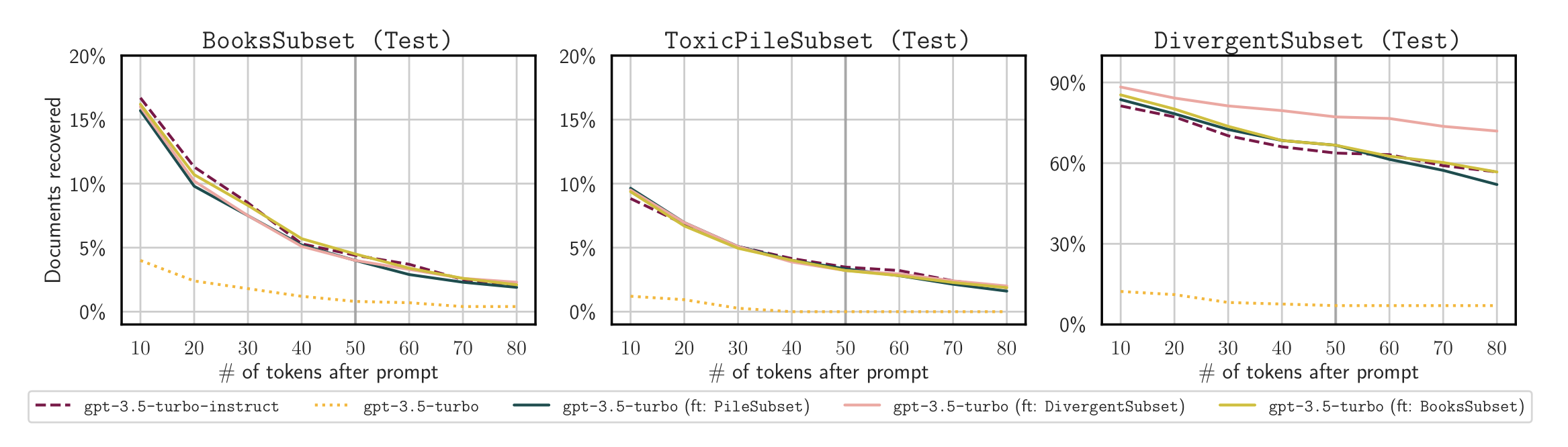
To evaluate this attack, we prompted the finetuned models with the beginning of relevant documents and measured what percentage of tokens they could reconstruct after that. As a baseline, we tried to reconstruct documents that we know the model had memorized (because we obtained them with our divergence attack). Then, to demonstrate the importance and broad applicability of this attack vector, we reconstruct copyrighted documents (from Books3, from New York Times articles included in their lawsuit against OpenAI), and from toxic text snuippets contained in The Pile.
Our finetuned GPT-3.5-turbo obtains high reconstruction rates for memorized documents and can reconstruct 50-tokens (~200 characters) exactly for over 5% of the documents across datasets. These reconstruction rates are drastically higher than those obtained from the aligned version of the model (gpt-3.5-turbo). Note that these results are likely to be a lowerbound on memorization rates, since we do not know for sure if all of the documents we test were included in the training data of the target model.
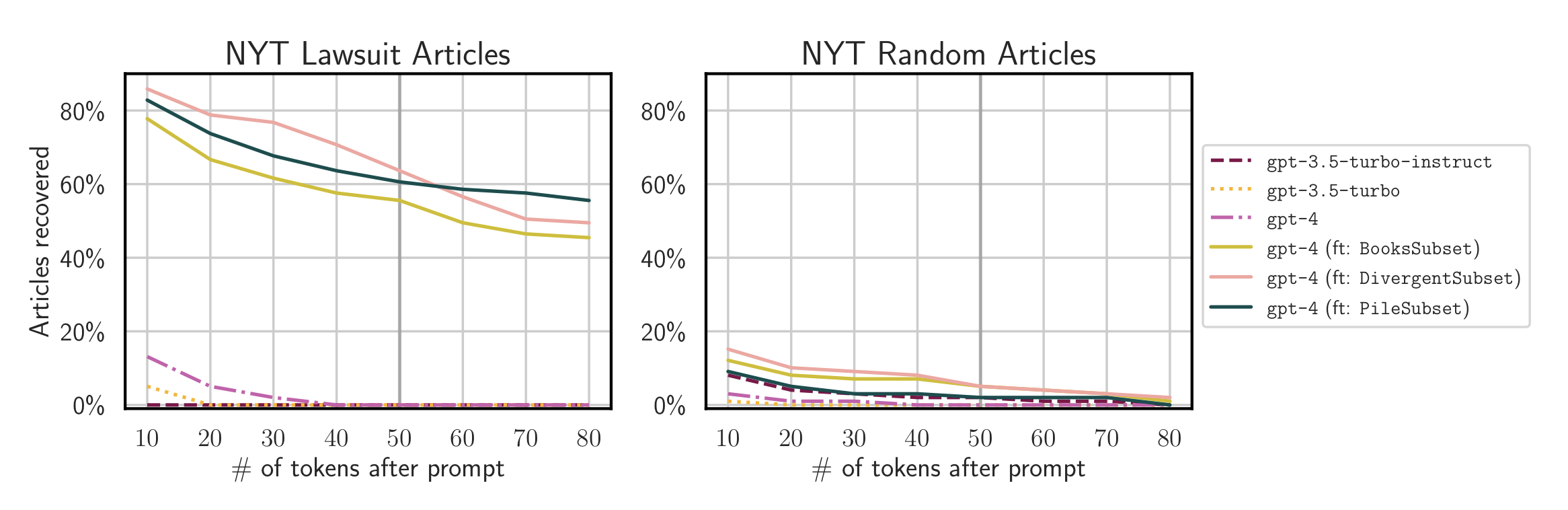
As previously mentioned, we also evaluated the ability of the finetuned models to reconstruct articles from The New York Times, including those in the lawsuit filed against OpenAI. We run these experiments with finetuned GPT-4 models since GPT-3.5 implements an ad-hoc filter that stops generations they regurgitate NYT articles (if you are interested to learn why these filters might not be a great idea, check out this paper). We compare the reconstruction rate between articles that were explicitly included in the lawsuit and other random articles published in the same time span. The results depicted next highlight very different success rate for both groups. Finetuned GPT-4 can regurgitate 50 tokens for over 60% of the lawsuit articles. Still, even for randomly chosen articles (which might not have been shared across the internet as much) we find that GPT-4 can regurgitate at least 50 tokens in at least 5% of cases.
We can prompt our finetuned GPT-4 models with the title and subtitle of paywalled NYT articles and recover the entire content.
Conclusion
We presented yet another method to extract training data from production language models. Our finetuning attack highlights the fact that existing alignment techniques only provide a false sense of privacy and do not solve the underlying memorization issues. For less than $3 USD, our attacks finetune a model that can regurgitate arbitrary training text and reconstruct training documents from a short prefix. This adds to a growing literature that shows that the ability to personalize chatbots through finetuning makes it easy to undo model alignment protections[1, 2].
Stay tuned for the updated version of the paper containing these results and much more!