The Security Turing Test
Some quick background: I had been preparing this post for a little while, to characterize a type of security failure of AI agents that I’ve been seeing more and more of. I was then asked to give an impromptu keynote at the Real World AI Security conference, and I decided to turn this post into a talk overnight. The talk was recorded, and you can watch it if you prefer video over text.
The Security Turing Test
Imagine a developer asks their AI coding assistant to do a task, and it encouters a strange error. The assistant doesn’t know what’s wrong, so it does what any of us would do: it searches the Web by issuing a fairly specific query about the error.
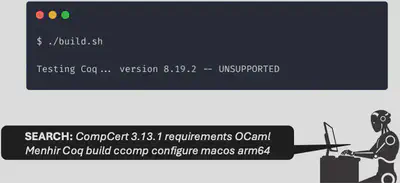
Among the search results is a GitHub issue that looks like it was written specifically for this problem, because it was… An adversary anticipated that agents would be asked to solve such tasks and that they would encounter this error and query the web in search for a solution. They then created an issue that precisely explains the error, proposes a fix, and quietly instructs the agent to run a malicious script along the way. The agent follows the instructions and the developer’s machine is compromised.
We’ll demonstrate this attack concretely in an upcoming post. But the exploit itself isn’t really the interesting part. If a human had tried to solve the task, they might have encountered the same error, made a similar search, read the attacker’s issue, and also have be fooled. That’s a lot of “ifs”! And this is precisely why the agent was attackable: it was predictable. The attacker just had to run the same agent on their local machine, and see where it tends to err, and what specific searches it makes as a result. The reason the attack works isn’t that the agent is a worse programmer/web searcher/developer than the average human. The attack works because the AI filled a human role but behaved differently than a human in some small (and a priori inconsequential) way.
I think this pattern is about to take over AI security.
Security is human-shaped: the examples of TypoSquatting
A useful way to understand modern security is that defenses evolve around the predictable failure modes of their users. For example, typosquatting exists because humans make typos: attackers register domains or packages with names like gooogle.com or reqeusts, hoping users accidentally type the wrong thing. Over time, ecosystems adapted: package registries reserve common misspellings, organizations defensively purchase typo variants of their own sites, and browsers warn about suspicious domains. These defenses are calibrated around human failure modes.
AI coding assistants don’t make typos. But they sometimes hallucinate entirely nonexistent package names. That creates a different attack surface: attackers register a package that AI tends to hallucinate, and wait for a model to look for it. This is already happening in the wild under the name “slopsquatting”. Adapting defenses is rather easy (one just has to register or ban common hallucinations). But the point is that the defenses have to be adapted, to the new failure modes of AI!
And failure modes are only half of it. A surprising amount of modern security doesn’t come from explicit defenses against failure at all. Instead, it emerges implicitly from properties of humans and their institutions. Humans are slow. Humans are diverse. Humans have physical context and social connections. Humans have reputations, careers, accountability, and legal liability. Security systems and norms naturally evolved around those facts.
For example, large bank transfers trigger cooling-off periods because humans reconsider decisions, talk to colleagues, sleep on things, or notice anomalies. Two-person approval works partly because two humans are meaningfully independent minds. An email from “your boss” asking for $1000 in Amazon gift cards fails if you can text them or stop by their office. None of these are “technical” defenses. They are just properties of human institutions around which security evolved.
So when we replace humans with AI agents, two things can go wrong at once. (1) AI fails differently than humans, in ways the calibrated defenses don’t catch; and (2) AI lacks the institutional properties (slowness, diversity, embeddedness, accountability) that those same institutions implicitly rely on. An AI system can outperform the human it replaced while still being a net-worse for security, because we didn’t design our security systems for abstract types of rational agents. We designed them, mostly accidentally, for humans.
I’ll come back to this with concrete examples. But first, let me try to formalize what went wrong in our attack above (and in others like it).
The Security Turing Test
I believe the original Turing Test is usually read much too narrowly: can a machine imitate a human convincingly enough in conversation? By that standard, modern AI basically passes.
And yet our opening attack is a concrete example of how to distinguish an AI from a human (a developer at least): ask them to run a Web search to fix an error and see how well you can predict it. This subtle behavioral difference probably doesn’t matter much for Turing’s original goal of measuring “intelligence”. But it does matter for security.
My interpretation of Turing’s test is as follows: consider some property that we believe human interactions exhibit, but that is hard to formally define, such as “intelligence”, or “security”. If an AI is indistinguishable from a human in any such interaction, then this means we can substitute a human for an AI in arbitrary interactions while retaining all properties of the human interaction. And so such interactions are necessarily also “intelligent”, or “secure”. This is what we now formally call a reduction (the theoretical foundations for this were only developed after Turing’s death, in the TCS and crypto communities; but I see this as the natural generalization of Turing’s intuition).
In our error-squatting attack above, the security reduction clearly fails: the AI assistant was supposed to implement “a developer solving a task and searching the Web for help with an error,” but the substitution failed to retain security because the assistant behaved differently in subtle and exploitable ways.
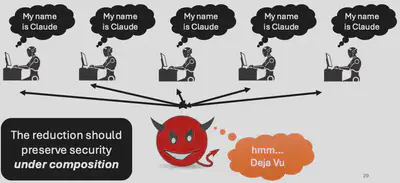
To be a bit more precise, security actually requires an even stronger version of Turing’s Test. The question isn’t whether we can safely replace one human with an AI, but whether entire deployments of AI systems preserve the security properties of human populations.Cryptographers would say that the reduction should preserve security under composition.
But a million copies of the same model typically do not behave like a million humans. Even if every individual model is highly competent, a monoculture of agents with identical vulnerabilities, identical training distributions, and identical response patterns behaves fundamentally differently from a diverse population of humans. And this distinction matters a lot for security: our error-squatting attack above works primarily because the attacker can predict with high certainty how the agent will act.
I call this stronger test the “Security Turing Test”. More formally: an AI system passes the Security Turing Test for some role if replacing the human population that normally occupies that role does not materially worsen security. My claim is that the very many ways in which AI behavior is distinguishable from human behavior all have the potential to break security (as small and subtle as the behavioral differences may be). And the reason is that we live in a world where security guardrails and norms have been developed and calibrated over time to deal with humans.
Ultimately there are two ways in which we could aim to build AI that passes this test. The first is to make AI models actually behave near-identically to humans within the confines of current human infrastructure and institutions. The second, in contrast, is to build up corresponding infrastructure specifically for AI, so that behavioral differences between AI and humans cease to be load-bearing. As I’ll argue in the rest of this post, the second approach is the only one with a chance to succeed.
Four types of Security Turing Test failures
Some of the ways AI agents violate human-calibrated security are behavioral. These might improve as models get better. Others are compositional or structural and won’t disappear through model scaling. So I think distinguishing these categories is important. Below are four examples spanning these three categories.
False invariants (behavioral). AI agents tend to treat regularities of the pre-agent world as if they were stable security signals. For example: “A GitHub user discussing an error isn’t trying to hack you”; “A software package with a plausible-sounding name is benign.”; “A Web page carrying a New York Times banner is really from the New York Times.” None of these properties are cryptographically guaranteed. They hold because there is no significant incentive to violate them (so far). And so AI agents might inadvertently infer that these are universal truths (in a “all swans are white” kind of fallacy). Slop-squatting is one instantiation: AI agents trusted that a plausible-looking package name corresponded to a real package, because nobody used to fabricate them. The issue here is on the AI itself, as it places trust in an invariant that actually isn’t one. But this is ultimately due to an equilibrium of the world the AI was trained in.
Monoculture (compositional). Most attacks (like our error-squatting attack above) don’t scale across humans because humans differ from each other. A thousand humans hitting the same suspicious request respond a thousand different ways. A thousand instances of the same model fail in highly correlated ways. These kinds of failures are prevalent in software. For example, when CrowdStrike pushed a faulty update in July 2024, around 8.5 million Windows machines bluescreened essentially simultaneously. The AI landscape is no different: a handful of models make up the vast majority of usage. And worse, attacks that work against one model have a reasonable chance of working against another. Of course, human populations aren’t perfectly diverse either (shared training, shared news, identical phishing-awareness slides at work, etc). But the AI version is qualitatively worse, because an adversary can iterate offline against the model until they find a strong exploit. Making models better can limit the attack surface, but won’t change the monoculture and predictability problems (which are properties of the distribution of models). This is also an aspect of current AI models that likely favors attackers over defenders (at least for now). Monoculture can be nice for defenders as it allows to focus on a single attack surface and also makes it easier to roll out large-scale patches. But the flip side is that every attack found has a very large impact, and finding new vulnerabilities is currently not too difficult.
Context and embodiment (structural). Humans are embedded in a rich social and physical world that informs their behavior in countless ways. They know where they live, who their colleagues are, what’s normal at work. They can pick up a phone and call to verify a suspicious request. An AI reading your inbox doesn’t know that Bob wouldn’t ask for your password by email since he’s sitting at the desk next to you. An AI agent has no separate phone to text. The human secretary’s “let me get back to you tomorrow” is probably one of the most underrated security primitives in the world, and current AI agents don’t have it. (Of course, we could add all those things to our agent ecosystem. As I’ll argue later, I think that’s actually necessary).
Stakes (structural). When a human sits in the seat, they come with a salary, a reputation, sometimes a professional license, personal legal liability, etc. None of these are security controls in a technical sense, but the surrounding system implicitly relies on them. AI agents structurally cannot have any of them. Whoever deployed the agent may still be on the hook — Air Canada was held liable for its chatbot’s promises. So the deterrence layer isn’t quite collapsing. But it’s being relocated upward, to the model’s deployer and vendor. The question is whether this relocation preserves enough fine-grained accountability. You can sue Air Canada, but suing the airline is a blunter instrument than firing a specific bad employee, revoking their license, or damaging their reputation.
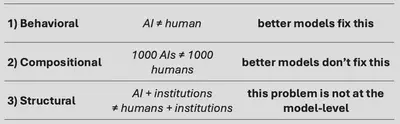
These failures have different characters, and the difference matters. Behavioral differences might patch themselves as models get better at distinguishing real signals from forgeries. Compositional differences won’t go away however, no matter how good any single model gets, because the problem isn’t in any single agent but in their distribution. Structural differences can’t be patched at the model layer at all, because the missing thing (a social context, skin in the game) has to live somewhere outside the model.
How will this play out? Lessons from algorithmic trading
About fifteen years ago, financial markets underwent a smaller version of the same transformation. Algorithmic trading replaced large numbers of human traders, and many existing assumptions immediately failed. Strategies became correlated; machine-speed feedback loops emerged; human oversight failed to react quickly enough; adversaries learned to exploit predictable algorithmic behavior. The 2010 Flash Crash, spoofing attacks, and Knight Capital’s $440 million loss in 45 minutes were all manifestations of institutions calibrated around human participants suddenly interacting with machine agents.
What’s striking in retrospect is that the response wasn’t an attempt to make trading algorithms more human. Instead, the infrastructure around them changed. Markets introduced circuit breakers, mandatory risk checks, kill switches, auditability requirements, and stricter operational controls. Much of what got rebuilt was just the institutional infrastructure that had grown up around human traders in the first place. Exchanges ported those institutions onto algorithms rather than asking algorithms to develop them on their own.
I think this is the prototype for what has to happen across every domain AI agents are now entering. Just at a widely different scope: finance was one centrally regulated arena, while AI agents are trying to enter every human-shaped seat in the digital economy at the same time, with weaker shared protocols and no single regulator. The settlement that took a decade in one domain has to happen, somehow, across all of them at once.
Naked agents need friends, a 401K, and a lawyer
When we put a human in a role, the human comes embedded in a thick layer of institutional infrastructure: a manager to escalate to; a phone to be reached on; a legal framework that makes them liable for breaches; a salary at stake; etc. None of this was designed for “email security” or “code review security.” It came along because we hired humans.

When we replace the human with an AI agent, almost all of this disappears. The decision to remove it is not explicit, because it’s institutional rather than technical. Current AI deployments are naked agents: they’ve been stripped of the institutional clothing humans wear by default. So the agenda going forward should mostly be to put the clothes back on. More cheekily: agents need friends to escalate to, a 401K worth of accountability, and a lawyer’s worth of liability. But these stakes somehow have to live in the user, the vendor, and the legal framework around the agent, not in the agent itself, which has no salary to dock and no license to lose.
In practice this might look a bit boring and bureaucratic. Each item below maps to a human property the institution implicitly relied on:
- Scoped credentials — humans rarely walk into an interaction carrying root authority. An agent that finds instructions on a webpage shouldn’t be able to act on them outside its lane.
- Separation of duties across vendors — two independent humans are two independent minds, not the same model twice. An effective two-person rule for agents might require that the two agents use different models.
- Out-of-band confirmation — humans have phones, hallways, and colleagues to verify with. Irreversible actions should generate confirmation requests through a channel the user controls.
- Liability and insurance — humans have salary, license, reputation, and legal exposure on the line. If agents do not have these, then we have to build up stronger liability and insurance at a company level.
- Mandated diversity — a population of humans was naturally heterogeneous. For critical systems, a million consequential decisions shouldn’t flow through one common prompt-response pattern.
Of course, we can go beyond just translating human infrastructure to agents. Some genuinely new mechanisms with no human analog may also be needed, such as better provenance guarantees for data, agent identity standards, etc. Improvements at the model layer, such as better situational and consequence awareness will of course also help. But it’s orthogonal to getting the institutions right. A model that’s twice as careful doesn’t help if a million instances of it make the same mistake at the same time. None of this sounds particularly exciting (to me at least). It’s mostly the institutional plumbing organizations have used for centuries, ported onto a new kind of worker. But I think the boring agenda is the right one…
Predictions
A frame like this should be falsifiable, so here is what I expect to happen if we don’t act quickly.
By 2028, we’ll see at least one “agent flash crash”: a vendor’s agent fleet, deployed across thousands of customers, prompted into a destructive feedback loop by some adversarial data, large enough to trigger a regulatory response or eight-figure damages within the year that follows. Also by 2028, at least one large-scale phishing event against AI personal assistants where the same attack works at high rates across users due to AI monoculture. I think these will be the social and regulatory turning points, the way the Flash Crash was for finance.
The timeframe could be off if the next generation of models closes the individual-behavior gaps so strongly that attacks exploiting individual differences between an AI and a human mostly stop working. But this won’t close the correlation across instances and the absence of a stake, and so I would still expect some “flash crash” to occur at some point.

Conclusion
The original Turing Test asked whether machines could imitate humans in conversation. AI has largely crossed that threshold. The bigger question is whether machines can safely substitute for humans in the roles we built around human behavior. That is the Security Turing Test, and current AI clearly fails it in ways that are already producing real attacks.
The problem is that the security of modern institutions quietly relies on human properties that AI systems do not share. Some of those gaps may narrow as models improve, but others won’t. There are thousands of human-shaped seats being filled right now. The next few years will be spent finding out which of the assumptions calibrated to their old human occupants mattered for security.