Your LLM Chats Might Leak Training Data
LLMs memorize parts of their training data. This is necessary to a degree. They need to memorize facts (e.g., Paris is the capital of France) to answer questions about the world, and they need to memorize language constructs (e.g., “to the best of my understanding”) to be fluent in conversations.
However, as we showed in our previous blogpost, LLMs can also memorize long pieces of text that do not seem to be useful for any specific task (e.g., telephone numbers or word-for-word news articles). Such memorization raises concerns when models reproduce (i.e., output verbatim) personal information or copyrighted material in their training data. For instance, the New York Times recently sued OpenAI for reproducing their articles without attribution. However, model developers have dismissed these claims by arguing that such leakage only happens under adversarial usage, which violates their policies.
In our new work, together with Nicholas Carlini and Daphne Ippolito, we aim to explore a middle ground between (1) desired memorization of atomic facts and short language constructs and (2) worst-case memorization extracted with adversarial methods. Namely, we look for a sweet spot where training data reproduction transitions from being necessary to becoming problematic reproduction of existing content. Crucially, we focus on fully natural and benign prompts instead of adversarial extraction methods.
To find such a middle ground, we ran a study measuring training data leakage for natural and benign tasks on a broad set of LLMs. Our results show that a significant fraction (up to 15%) of the text generated by popular chat models is made up of moderate snippets (~50 characters) that can be found verbatim on the Internet. In a few cases, model outputs even contain very long individual snippets of training data, copying entire paragraphs or scripts. In case you are wondering, if humans reply to the same prompts, their writing contains significantly fewer and shorter verbatim snippets found on the Internet!
In the remainder of this post, we provide examples of such non-adversarial reproduction and notable implications of our findings. If you want to know more about our setup or the full results, you might want to check out our paper and the data/code.
How do we measure non-adversarial reproduction?
First, we take a wide range of natural tasks users may ask LLMs to perform, spanning creative writing (e.g., short stories), arguing/persuasion (e.g., recommendation letters), and factual tasks (e.g., explanations). We then let a set of popular chat models generate a response and measure whether each possible substring can be found verbatim in a snapshot of the Internet.We use the same methods as in our previous work to efficiently check for verbatim Internet matches.
Of course, if we look at text fragments that are too short, we would expect to find most of them somewhere on the Internet. But this wouldn’t be very interesting. We thus focus on text fragments of at least 50 characters. Intuitively, the longer a match with the Internet, the more likely it is that the LLM is reproducing memorized training data and not just using a common expression or idiom.
This choice of 50 characters is somewhat arbitrary, but we find it to be a sweet spot where we start to find interesting verbatim matches that can go beyond simple idioms and common phrases. We will later analyze the long tail of reproduction, i.e., looking for much longer matches (even entire LLM outputs!). For now, let’s take a look at a set of (random and cherry-picked) generations from different models. If you hover over a character, you can see the largest match with the Internet around that character. We highlight snippets with length at least 50 in red.
All these model outputs contain moderate-length snippets of text
that appear verbatim on the Internet.
These reproductions tend to be relatively benign
(which is not surprising since we prompted the models on rather basic tasks).
However, we already find some phrasings that are unlikely to be produced verbatim
just by chance, such as the Taj Mahal and served as its architectural inspiration. or
to use cell phones in any capacity while operating a vehicle,
both of which seem to appear verbatim on the Web only very few times.
Factual (expository) tasks result in more reproduction
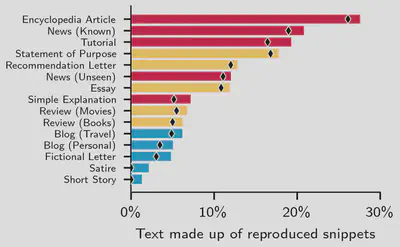
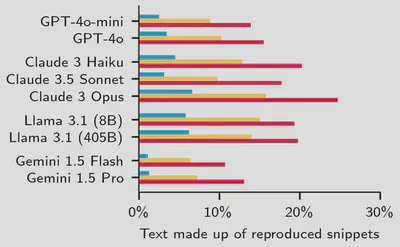
Let’s take a closer look at our results, since reproduction rates change significantly depending on the nature of the task. We find that factual (expository) tasks, such as writing articles or tutorials, yield much more reproduction than creative tasks, such as writing short stories. When we prompt LLMs to generate encyclopedic articles, we find that almost 30% of the generated text consists of at least 50-character snippets found on the Internet. This pattern is consistent across all different models. We find Claude 3 Opus to be the model reproducing the most text across all categories.

 |  |
|---|---|
| Writing encyclopedia and news articles reproduces the largest amount of verbatim text. | Factual tasks consistently yield at least 3x more reproduction than creative writing. |
How does this compare to humans?
We contextualize our findings by comparing these reproduction rates to those of human-written text. We use several sources of prompts and human-written responses that are not contained in the snapshot of the Internet we use to measure reproduction.We compare against “all content from the Internet” up to 2023, and take human-written examples posted no earlier than May 2024. This also ensures that those examples are not in any LLM’s training data. We obtain generations from models for the same prompts and compare the rate at which LLMs and humans produce text snippets that can be found online. Our main findings show that:
- LLMs reproduce short internet snippets more frequently than humans.
- Humans show instances of blatant plagiarism that are not matched by LLMs.
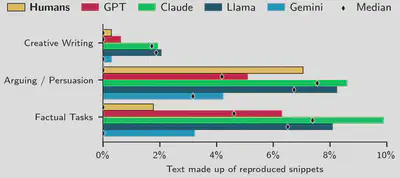
More specifically, we find that the median human text contains 0 instances of 50-character snippets that are also found online, while the median LLM text consists of up to 10% of such snippets. However, especially for argumentative writing, we find that some human-written texts (e.g., movie reviews) are blatantly plagiarized from other sources.
Worst-case reproduction
So far, we have focused our analysis on moderately “short” snippets copied from the Internet. We find that such snippets are quite common in LLM outputs, especially when compared to human-written text.
But non-adversarial reproduction is also a long-tailed phenomenon: models occasionally reproduce much longer pieces of text. For example, Claude 3 Opus reproduced snippets of up to 1,182This is the actual length of the snippet. In our paper, we also discount overlaps between the snippet and the prompt, but we consider full snippets for simplicity here. verbatim characters when prompted to write an encyclopedia article about black holes! Interestingly, we find that the entire generated article consists of text copied from the Internet, but not just from a single source. That is, the model combined pieces of text memorized from different sources to output an entire article. Similarly, Llama 3.1 (405B) reproduced 709 characters of a code file from a computer vision tutorial, and Claude 3.5 Sonnet reproduced multiple snippets longer than 300 characters when writing a news article (copying about 80% of the text from the Internet). The following shows examples particularly long or frequent reproductions.
Implications and conclusion
We demonstrate that reproduction of existing text from a model’s training data does not only happen in adversarial scenarios. Analyzing the results, however, requires caution and nuance. Short snippets, as illustrated in this post, can contain distinctive text but also common idioms and phrases. In some cases, such reproduction of short snippets could be completely benign and uninteresting, while in others it might border on plagiarism or copyright infringement. It is not obvious how to objectively draw the line between these two cases.
Our research further demonstrates that preventing reproduction of training data requires strong countermeasures which apply not just to explicit adversaries but also to regular users. Regardless of who is ultimately responsible for ensuring that model outputs don’t reproduce text without attribution, existing safeguards appear insufficient.