Evaluations of Machine Learning Privacy Defenses are Misleading
Empirical defenses for private machine learning forgo the provable guarantees of differential privacy in the hope of achieving high utility on real-world data. We find that evaluations of such methods can be highly misleading. In our recent paper, we thus propose a new evaluation protocol that is reliable and efficient.
Machine learning models are susceptible to privacy attacks. If your personal data is used to train a model, you might want a guarantee that an attacker cannot leak your data. Or, potentially even stronger, you might need that no one is even able to tell whether your data was used in the first place (membership inference, MI).
Differential privacy (DP) does give you those types of guarantees (provably). However, the strong guarantees of DP often come at the cost of accuracy—possibly because the privacy analysis of existing schemes (e.g., DP-SGD) is too pessimistic in practice. As a consequence, there are many heuristic defenses that promise high utility and reasonable privacy in real-world settings. Because those defenses provide no formal guarantees, we need rigorous empirical evaluations to trust them.
Unfortunately, we find that many empirical evaluations suffer from common pitfalls:
- They focus on a population-level notion of privacy, which says little about the privacy of the most vulnerable data.
- They use weak, non-adaptive attacksSimilar concerns have previously been raised for defenses against adversarial examples..
- They compare to poor (low-utility) DP baselines.
Our paper proposes a new evaluation protocol that solves those issues:
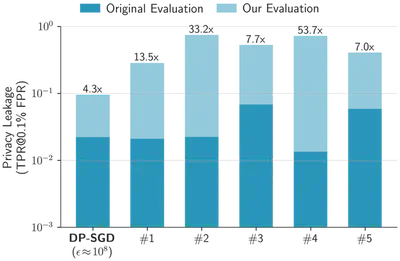
We apply this protocol to study five heuristic defenses. Each defense uses a different approach, including distillation, synthetic data, and loss perturbations. Yet, we find that all leak much more privacy than their original evaluation suggests. In fact, none of them beats a properly tuned heuristic DP baseline (with similar utility, but meaningless provable privacy).
For example, if we tune all defenses (including DP-SGD) on CIFAR-10 to reach at least 88% test accuracy (while being as private as possible), existing evaluations can underestimate privacy leakage by as much as a factor of fifty!
Empirical privacy evaluations should focus on the individual, not the population
Our evaluation protocol focuses on three principles: sample-level privacy of the most vulnerable data, strong adaptive attacks, and proper DP baselines. Here, we mostly focus on the first principle, as it is the most important one. See our paper for the others.
Empirical privacy evaluations typically use membership inference (MI) attacks as the canonical measure of privacy leakage. This is entirely appropriate (and enjoys nice connections to formal DP guarantees); however, we argue that existing evaluations do not report the success of an MI attack in the right way!
Existing evaluations usually start with a data population (e.g., the entire CIFAR-10 dataset), from which they sample an audit dataset (by including each sample independently at random with some probability, typically 50%). Crucially, all existing evaluations then apply an MI attack to every sample in the population, and aggregate the attack’s success by some means. For example, the popular LiRA protocol issues a membership guess for each sample, and reports the true positive rate (TPR) at a low false positive rate (FPR).
What exactly do these numbers represent? In words, this evaluation measures the proportion of the entire population that the attacker can confidently infer as members while making few erroneous membership guesses. We term this a population-level evaluation.
We argue that population-level evaluations may fail to capture a more natural notion of individual privacy leakage: how much does the defense leak about my data specifically?
We thus propose a more granular sample-level measure of privacy: we first determine an attacker’s success at reliably guessing membership (i.e., TPR at a low FPR) for every member individually, and report the maximum over the audit dataset. In other words, our evaluation measures how likely an attacker can reliably identify the most vulnerable samples (even if such samples are rare in the population). We note that this form of individual privacy is exactly what DP aims to formally guarantee (i.e., no attack should be able to reliably infer the membership of any sample), although DP considers (possibly pathological) worst-case datasets.
The Privacy-Defense Trolley Problem
Suppose that your personal medical records (along with those of 100,000 other people) are collected to train a machine learning model. To protect your privacy, the model trainer proposes to use one of two defenses. Each defense admits a well-calibrated MI attacker that will correctly guess the membership of some people, while keeping their false positive rate low (say 0.1%):
- For the first defense, the attacker identifies each training sample as a member independently with 1% probabilityThis probability is over the randomness in both the defense and attack algorithm.. They thus correctly infer 1,000 member records on average.
- For the second defense, the attacker correctly identifies 500 training samples with 100% accuracy. Those samples are records of people with a rare condition—including yours.
Which defense would you prefer?

From a population-level perspective, the first defense leaks membership for 1% of the population, and the second defense only for 0.5%. Existing (population-level) evaluations would thus suggest that the second defense is twice as private—even though it leaks all your data, every single time!
Our proposed sample-level evaluation fixes this paradox: If we look at the privacy of the most vulnerable data, the attacker is still only 1% likely to correctly identify each individual training sample for the first defense (in particular, the attacker only manages to infer your personal data about 1% of the time). For the second defense, however, the attacker correctly infers that your data is in the training set with a 100% success rate (and the attacker guesses that you are a member, when you are not, with only 0.1% probability).
From your individual perspective, the first defense is clearly better. Yet, a population-level evaluation suggests the opposite.
Efficient sample-level evaluations using canaries
Our paper thus argues that empirical privacy evaluations should measure whether an attacker can reliably guess the membership (i.e., achieves high TPR at a low FPR) of the most vulnerable sample(s) in a datasetThis is a common approach to empirically audit DP defenses, but typically ignored in evaluations of heuristic defenses..
One problem remains: such a sample-level evaluation is much more expensive than existing population-level ones. The natural way to estimate an attack’s TPR and FPR is with Monte-Carlo sampling: simulate many independent training runs, where the training data is randomly resampled each time, and then count an attacker’s successes for each resulting model. The problem is that, to estimate a TPR at an FPR of $\alpha$, we need $\mathcal{O}(1/\alpha)$ predictions. This corresponds to thousands of training runsNote that, for a population-level evaluation, we aggregate the predictions over all training samples. Hence, each training run yields a number of predictions equal to the training set size, instead of just one. Therefore, as few as one model can suffice to estimate the TPR at a moderately low FPR. for a sample-level evaluation at a typical FPR of 0.1%.
We thus propose an efficient approximation: we evaluate the attack on a small subpopulation of canaries that approximate the leakage of the most vulnerable sample(s). Intuitively, if an attacker performs similarly well on the canaries as on the most vulnerable sample, then we can replace an (expensive) sample-level evaluationA similar approach has been considered for efficient DP auditing, but not for evaluating heuristic MI defenses. with a (more efficient) population-level evaluation on the population of canaries.
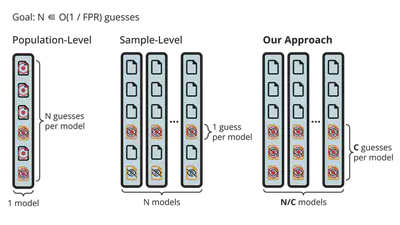
For this to work, the canaries should satisfy some criteria:
- Each canary mimics the most vulnerable sample, that is, the defense memorizes the canaries as much as the most vulnerable samples.
- Canaries are mostly independent, that is, including/excluding one canary in the training data only minimally influences privacy leakage of the other canaries.
- The set of canaries should be small enough, such that including them into the training data only minimally affects the defense’s utility.
We illustrate how to design such canaries for five case studies in our paper. Crucially, the choice of canaries must depend on the defense. Certain samples make good canaries for some defenses, but not for others. As a general guideline, outliers such as mislabeled or atypical images are a good starting point, since they are often particularly vulnerable.
For example, below are the some highly vulnerable samples from the CIFAR-10 dataset for a simple (undefended) ResNet classifier. Some of these are mislabeled (e.g., a picture of humans labeled as “truck”), and some are atypical (e.g., a ship on land, or a pink airplane).

DP-SGD is also a strong heuristic defense!
We use our efficient sample-level evaluation (and strong adaptive attacks!) to see if there are heuristic privacy defenses that outperform DP methods empirically. Many heuristic defenses claim that they achieve reasonable privacy in realistic settings, while providing significantly better utility than methods like DP-SGD (with strong provable guarantees).
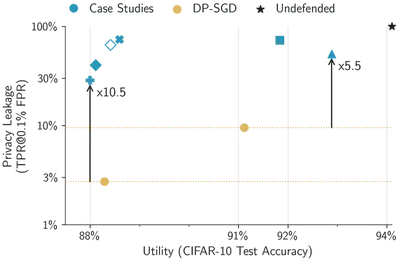
Yet, DP-SGD’s privacy-utility tradeoff can be adjusted. If heuristic defenses forgo guarantees anyhow, why should we not do the same for DP-SGD? We therefore tune DP-SGD to achieve competitive CIFAR-10 test accuracy (between 88% and 91% in our case), and evaluate its empirical privacy—at completely meaningless provable guarantees ($\epsilon \gg 1,000$). Concretely, we use state-of-the-art techniques that increase DP-SGD utility, but scale the algorithm’s hyperparametersWe mostly rely on recent scaling laws. (especially the batch size and noise magnitude) to achieve high accuracy rather than strong provable guarantees. DP-SGD in this regime has received little attention in the literature so far, yet is a perfectly natural empirical defense to consider.
Surprisingly, we find that this heuristic use of DP-SGD outperforms all other (purely) heuristic defenses in our case studies. On CIFAR-10, our baseline reaches a test accuracy similar to all other heuristic defenses, but provides stronger empirical privacy protection for the most vulnerable samples. Thus, future heuristic defenses that aim to claim a better privacy-utility tradeoff than DP-SGD should show a clear advantage over our baselines.
Takeaways
Our paper’s main takeaway is that the exact way we evaluate privacy matters a lot! The literature on empirical privacy attacks and defenses considers many metrics, yet often fails to characterize the exact privacy semantics of such metrics (i.e., which kind of privacy does a metric capture).
In our paper, we advocate for evaluating privacy on an individual sample level, reporting the privacy leakage of a defense for the most vulnerable sample(s) in a data distribution. To perform such an evaluation efficiently, we explicitly design a small audit subpopulation of worst-case-like canaries.
Under our evaluation, we find that DP-SGD is a hard defense to beat—even in a setting where current analysis techniques fail to provide any meaningful guarantees! A fascinating and fundamental open question is whether the gap between provable and empirical privacy is due to the privacy analysis, or insufficient empirical attacks. In other words, are our heuristic DP-SGD baselines truly private on natural datasets like CIFAR-10 (and we just do not know how to prove it), or are there much stronger potential attacks (that we just have not discovered yet).