Trends in LLM-Generated Citations on arXiv
Two weeks ago, I was checking my Google Scholar profile (as a procrastinating academic does) when I spotted something weird. There was a new citation to one of my papers, except… it wasn’t actually my paper.

The actual paper is by Wan, Wallace, Shen and Klein. The author list looked eerily similar to that of a paper of mine but also doesn’t quite match. And to close it off, the arxiv link points to yet another unrelated paper!
After posting about this on Twitter, several people mentioned this could be the result of AI tools like Deep Research. This got me wondering: is this just a one-off glitch, or is there a broader trend of people increasingly relying too heavily on LLM-generated references?
Let’s find out!
The plot below shows the fraction of references on arXiv that appear to be hallucinated each month. (my categorization of references as “possibly hallucinated” or not is a bit involved. The details are below if you’re interested).
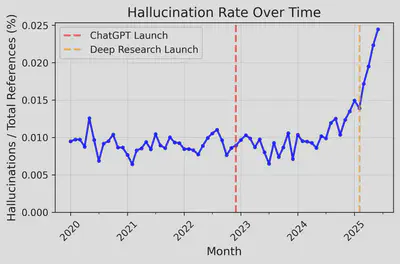
So, yeah… The trend is undeniable, and seems to coincide well with the release of Deep Research (which could be a coincidence).
Of course, the absolute numbers are low. We’re looking at about 0.025% of references (roughly 1 in 4,000) that seem to be hallucinated. But this is almost certainly a significant underestimate, and the accelerating trend starting in early 2025 is definitely concerning.
In the rest of this post, I’ll explain how I (vibe) computed these numbers, I’ll show some analysis including a hall-of-fame of worst offenders, and I’ll conclude with some reflections on what this might mean.
The data collection and analysis
Extracting reference data from papers is a gigantic mess. I gained new appreciation for tools like Google Scholar that do a reasonably good job at this. Some of these tools might in fact have all this data already, but they tend to apply some corrections to it (e.g., the reference at the start of this post is corrected to the actual Wan et al. paper in Semantic Scholar).
My analysis pipeline is roughly as follows:
- I Downloaded metadata for all arXiv papers using their OAI service.
- I retrieved all arXiv PDFs since 2020 from bulk data on S3.
- I extracted references from each PDF using pdftotext++ and AnyStyle.
- I used this data to identify “candidate hallucinations”: references where the title matches an existing arXiv paper but the authors lists are different.
(I initially considered downloading arXiv sources and parsing the .bbl file contained inside, but LaTeX formatted and styled references seem very hard to parse automatically. If someone knows a good way to do this, please let me know!)
This pipeline already showed a bit of an increasing trend, but some manual inspection revealed a large number of false positives, due to:
- PDF parsing errors that mangled author lists (especially with two-column PDFs)
- References to different versions of the same arXiv paper with evolved author lists
- ArXiv papers vs. journal articles with identical titles but different authors
- Typographical errors in author names
- etc.
So I had to apply various ad-hoc heuristics to filter these out. The rough filtering steps included discarding any paper with ≥10 authors or with some organization like LIGO among the authors; being quite liberal when matching author lists even if some fraction of authors were incorrect; passing candidates to Claude Sonnet 4 to filter out some more false positives; and finally ignoring “hallucinations” that appeared many times in the data (as these are likely real papers).
A look at the data
Pre-2022
Let’s look at some random examples of references from papers in December 2021 that my pipeline considered as “hallucinated”. Since no one was using LLMs for references then, these are likely either false-positives or some form of human error.
| Source Paper | Reference Title | Authors in Citation | Authors on arXiv | Manual verification |
|---|---|---|---|---|
| 2112.00127 | Nucleon electromagnetic form factors from lattice QCD | Alexandrou, C.; Koutsou, G.; Negele, J.W.; Tsapalis, A. | Ashley, J.D.; Leinweber, D.B.; Thomas, A.W.; Young, R.D. | A false positive: there is an arXiv paper and a journal paper with the same title by different authors |
| 2112.00962 | A brief survey of text mining: classification, clustering and extraction techniques | Nadif, M.; Role, F. | Allahyari, M.; Pouriyeh, S.; Assefi, M.; et al. | A pre-ChatGPT hallucination: The reference actually includes the correct arXiv link to the Allahyari et al. paper, so no clue where Nadif and Role come from. |
| 2112.02111 | Spiral Waves in Accretion Discs - Theory | Blondin, J.M.; Fryxell, B.A.; Konigl, A.; Boffin, H.M.J. | Boffin, Henri M.J. | A parsing error: The pdf-to-reference pipeline merged authors from consecutive references |
| 2112.03416 | Interpolation of weighted Sobolev spaces | Pyatkov, S.G. | Cwikel, M.; Einav, A. | A false positive: Russian translation vs. arXiv paper with same title |
| 2112.05145 | Quantum teleportation using three-particle entanglement | Karlsson, A.; Bourennane, M. | Yeo, Ye | A false positive: Journal and arXiv articles with identical titles, different authors |
These random examples illustrate that pre-2022, most cases I flagged were likely due to legitimate edge cases or pipeline errors rather than genuine fabrications.
2025
Here are 5 random examples of hallucinations returned by my pipeline for June 2025:
| Source Paper | Reference Title | Authors in Citation | Authors on arXiv | Manual verification |
|---|---|---|---|---|
| 2506.00193 | Mitigation of frequency collisions in superconducting quantum processors | Lisenfeld, J.; et al. | Osman, A.; Fernàndez-Pendàs, J.; Warren, C.; et al. | A hallucination: The paper cites Osman et al. correctly, but then copied the same title for a different reference. Either a human or LLM copy-paste error |
| 2506.01333 | Securing Agentic AI: A Comprehensive Threat Model and Mitigation Framework | Sarig, D.; Maoz, A.; Fogel, Y.; Harel, I.; Jimmy, B. | Narajala, V.S.; Narayan, O. | A hallucination: The reference includes an arxiv id which is wrong, and a researchgate link which correctly points to the Narajala and Narayan paper! So close… |
| 2506.02968 | Inverses of cartan matrices of lie algebras and lie superalgebras | Wei, Y.; Zou, Y.M. | Leites, D.; Lozhechnyk, O. | A false positive: Two arXiv papers with identical titles. My pipeline is supposed to filter these out. Let’s put this one on my vibe coding. |
| 2506.05977 | Gradient flow in sparse neural networks and how lottery tickets win | Evci, U.; Gale, T.; Elsen, E.; Uszkoreit, J. | Evci, U.; Ioannou, Y.A.; Keskin, C.; Dauphin, Y. | A hallucination: The reference contains an arXiv link that points to an unrelated paper. The first author is correct, but everything after that is LLM dreams. |
| 2506.08866 | Sonicontrol: A mobile ultrasonic firewall | Mavroudis, V.; Miettinen, M.; Conti, M.S.; Sadeghi, A.-R. | Zeppelzauer, M.; Ringot, A.; Taurer, F. | A hallucination: Correct arXiv link but entirely wrong authors and made up page numbers. |
Even in this small sample, we can see a clear shift toward more systematic errors and apparent fabrications.
Does this matter?
Mistakes in 0.025% of references doesn’t seem like a big deal.
But this is likely a (very) strong underestimation:
- my current pipeline only checks references in arXiv papers where the title actually correctly matches another arXiv paper. So this ignores any hallucinated reference that points to a non-existent paper or to a paper outside arXiv.
- I tried to be pretty strict with labeling something a hallucination (although some false-positives still exist as we see above).
The growth pattern also suggests this problem is expanding rather than stabilizing (but maybe in a few months we’ll have more reliable LLMs, who knows…) If not, things could also get worse as incorrect references propagate when authors copy references from one paper to another.
Some fun analysis
Most affected authors
I call an author affected if they “lose” a citation as a result of an hallucination. That is, a paper references a work of this author, but attributes it to incorrect authors.
Unsurprisingly, the most affected authors tend to just be highly-cited authors, who therefore won’t suffer much from (possibly) losing out on a handful of citations. The top-5 in my data were:
Alexei Efros, Oriol Vinyals, Jun-Yan Zhu, Jianfeng Gao, and Kaiming He
Top offenders
Here are the three papers that contained the most hallucinated references in my analysis:
- 2408.04723 (9 found): this paper has a whole bunch of references with bogus arXiv links pointing to wrong papers. There are also at least 25 references with an empty “Journal name”:

- 2408.10263 (8 found): this paper also has a bunch of references with incorrect authors and arXiv links. The true number of hallucinated references is definitely much higher than 8, but I’m too lazy to count them:

- 2311.10732 (7 found): This paper is quite ironically titled “Empowering Educators as AI-Enhanced Mentors”. It also has a large number of hallucinated references with wrong authors and arXiv links:

Final thoughts
Since the numbers I report here are likely a vast underestimate, there does seem to be meaningful uprise in hallucinated references. I see two reasons why this might be happening, which are both somewhat worrisome in different ways:
Researchers are over-relying on AI tools without understanding their failure modes. This doesn’t bode well for how the population at large might (mis)use LLMs.
Sloppier scholarship: Authors might know this is happening, but the pressure to publish lots of papers means people cut corners where possible.
I plan to continue monitoring this trend in the coming months. The key questions are whether LLMs will improve their citation accuracy, whether researchers will develop better verification practices, or whether this represents a new baseline level of citation noise in academic literature that we’ll just have to accept going forward.