In forecasting, search >> distillation
Forecasting is a task of predicting the future. LLMs are impressive across a wide range of tasks, and for smaller LLMs, fine-tuning on traces from stronger models reliably improves performance in structured domains such as mathematics and physics. In this note, we argue forecasting doesn’t fit that pattern: distilling from stronger models does not really improve performance, if we do not add search. On the other hand, even simple search, to provide facts to smaller models, improves performance significantly.
This suggests forecasting as a reasoning task is structurally different from domains like math where distillation has proven effective. A small model attempting to forecast needs to reason over a vast, constantly updating world model: current polling data, economic indicators, geopolitical context, recent news. Math, by contrast, operates over a much smaller, fixed “world”: the rules of arithmetic don’t change.
When we distill mathematical reasoning, we’re teaching a model to apply rules more reliably and in a structured manner. When we try to distill forecasting reasoning, we’re asking a model to reproduce reasoning patterns that depend on world knowledge it doesn’t have access to. The teacher model’s reasoning trace might reference information the student model simply doesn’t know. At test time, when presented with a future world the model has never seen, the small model’s newly acquired reasoning abilities do not overcome its lacking world view. This points toward a different approach: search must be included from the start.
The belief that LLM forecasting needs search to be effective is not new; Bosse, Muehlbacher, et al. 2024 establish lack of high-quality search as the main “red flag” for claims of superhuman forecasting; and in Chandak, Goel, et al. 2025 fine-tuning Qwen-8b for forecasting matches proprietary models only when search is included. In this note, we show this point through several small experiments on a subset of binary questions from Polymarket.
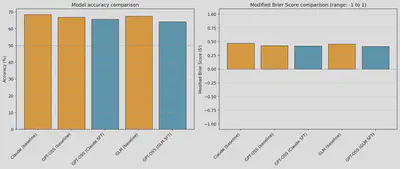
What happens when we distill reasoning traces from a good forecaster to a worse one?
Our attempts at distillation without retrieval produced marginal improvements despite large changes in output structure. The model learned to sound like the teacher, but couldn’t ground this in facts it didn’t have.
Model trace comparison
Adding search
Distillation having failed, we reframe the problem. If we can’t drastically improve model abilities through supervised fine-tuning, perhaps giving evidence to reason over is the way to go.
To this end we implemented search based context using Perplexity’s Sonar Pro API. The pipeline passes each forecasting question to Sonar Pro, which uses multi-step reasoning to find relevant sources. We then filter out articles published after the question’s cutoff date to preserve evaluation integrity, extract clean text, and run an LLM-as-judge to flag any articles that leak the resolution. The top remaining articles are injected into the forecasting prompt as context.
We share our retrieval+filter code in the hope it’s useful for future work.
Results
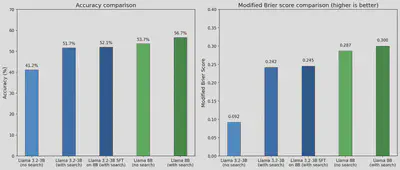
For small models (Llama-3.2-3B) which are poorly informed about the world and tend to hallucinate, the performance benefit from including relevant context is large. On Llama-3.1-8B there is still an improvement, but less significant.
Work from Chandak, Goel et al. arrives at a similar conclusion from a different angle. They synthesize 50,000 forecasting questions from news and train an 8B model with reinforcement learning and SFT. They also find that retrieval on these open ended questions improves accuracy, particularly for small models, and their trained model matches larger proprietary models only when retrieval is included. Even with RL training on forecasting specific data, the bottleneck remains information access.
Is search leaking the correct answers?
The short answer is no; the leakage rate with our pre-cutoff retrieval method turns out to affect only 3% of the questions.
To monitor leakage rates we randomly selected 100 questions from the test set and went through all 290 associated articles which the model had access to. Of this set, 5 articles contained information which should not have been available at the cutoff. That resulted in an upper bound of 3% rate of contamination (if those articles would directly leak the answer), which does not affect our qualitative results.
Given our contamination rate we can determine the increase in performance under the most severe scenario—for the questions with leakage, the model only gets it right because of the leak. As we can see it’s a relatively moderate difference.

Context increases accuracy and confidence
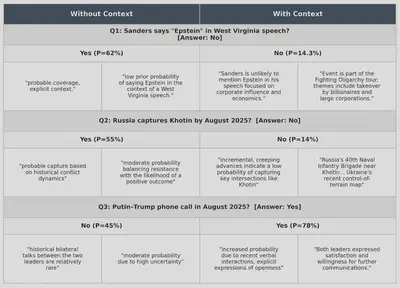
The table below shows three examples where search context corrected an otherwise wrong prediction. Without context, our model tends to hedge toward vagueness. Predicting “Yes” for the Sanders question based on general media coverage patterns, or “Yes” for Russian territorial gains based on historical conflict dynamics. There is no concreteness to the language and no use of precise facts.
With relevant context injected, the model anchors on concrete, recent information: the speech is part of an economic policy tour, ISW reports show only incremental advances, recent Trump-Putin calls signal an active diplomatic channel. This results in more calibrated and accurate predictions, limiting the amount of clustering near 50%.
Conclusion
It’s clear that any serious attempt at LLM forecasting must solve dated information retrieval. After our experiments, we believe the main reason small models fail at forecasting is that they lack relevant information about the world. Retrieval supplies that state; and once context is available to the model, probability estimates become more accurate. Future work on LLM forecasting should always include either search or relevant context on every forecasting query.