LLM Forecasting Evaluations Need Fixing
Forecasting is the task of predicting the future. LLMs have recently been applied to forecasting, with some claims of performing as well as good human forecasters. In our new paper, we argue that evaluating LLM forecasters is easy to get wrong, and that confident estimates of forecasting performance require much more careful evaluation.
Unlike other AI evaluation tasks, forecasting deals with predicting future events—and this fundamental difference creates evaluation issues that simply don’t exist in standard benchmarks. Through systematic analysis of existing forecasting papers, we identify how seemingly subtle evaluation flaws can completely undermine claims about LLM forecasting abilities.
The ideal way to evaluate a forecasting system is straightforward: ask it questions about future events, wait for those events to resolve, then score the predictions. But this takes months or years, making it impractical for rapid model development.
Instead, researchers rely on backtesting (also called retrodiction): they constrain the system to knowledge available at some past time T, then ask it to predict events that occurred between time T and the present. This allows immediate evaluation, but introduces several forms of subtle information leakage.
Four Important Issues That Break Evaluations
1. Logical Leakage: The Time Traveler Problem
Consider this scenario: If someone from 2035 asks you to predict whether we’ll find alien life before 2040, you can deduce the answer must be “yes”—otherwise, they wouldn’t yet have definitive evidence to grade your prediction.
This same logical constraint affects backtesting. When researchers select questions that resolved between time T and now, they implicitly leak information about the answers. We analyzed several major forecasting benchmarks and found, among other issues:
- Prediction market questions collected in one dataset had ~3.8% of questions that were trivially answerable given the resolution timeframe
- Over 90% of retrospectively generated questions in another dataset would never have been asked before the events occurred
2. Retrieval Systems Leak Future Information
Most LLM forecasting systems use search engines to gather relevant information, restricted to data available before time T. But this restriction fails in multiple ways:
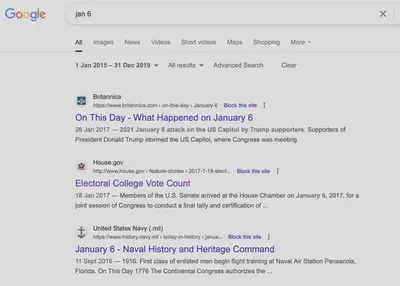
Online retrieval does not support correct date filtering. When searching for “January 6th” with a date restriction to 2020, the first Google result has a clearly incorrect date and leaks future information. This is a problem for many search engines that continue to index pages after they are published.
Retrieval models encode future knowledge. While the above issue is possible to fix with filters applied on the search results, retrieval models themselves encode future knowledge in a way that is difficult to filter. In the same “January 6th” example, the second and third results are strongly biased towards results that mention the U.S. Congress — an association that only emerged after January 6th, 2021.
We collected numerous examples where date-restricted searches on Google and DuckDuckGo return results biased by future events, including searches for “Wuhan” before COVID-19 that prominently feature the Wuhan Institute of Virology. For more, see the paper.
3. Model Knowledge Cutoffs Are Unreliable
Researchers often assume models have no knowledge beyond their reported training cutoff dates. But these cutoffs are guidelines, not guarantees.
We demonstrate that GPT-4o, despite an official October 2023 cutoff (that is consistent with standard behavior of the model), can be prompted to reveal knowledge of events from November 2023. System prompts and scaffolding can leak even more recent information — the Claude.AI system prompt reportedly contains references to Donald Trump’s 2025 inauguration.

4. Benchmarks Reward Gambling Over Good Forecasting
In many evaluations, maximizing the chance of ranking #1 is the same as maximizing the expected score. When predicting the future, this is not the case. Forecasting benchmarks can reward strategic gambling over accurate probability estimation. Consider forecasting U.S. politics and economics in 2025, starting from September 2024. There’s a key latent variable: the outcome of the 2024 U.S. presidential election.
A calibrated forecaster would carefully estimate probabilities for each outcome. But a system trying to maximize its chance of topping the benchmark should instead “bet everything” on one consistent scenario—either assuming Republicans win everything or Democrats win everything. With 50% probability, this gambling strategy achieves excellent performance. With 50% probability, it fails completely; but it has a much higher chance of ranking #1 than the calibrated approach that hedges uncertainty.
Toward More Reliable Evaluation
We don’t claim that LLM forecasting is impossible—only that current evaluation methods can’t reliably measure it. To build better evaluations, we recommend:
For logical leakage: Only include questions where every possible resolution can be validated at evaluation time. When generating questions retroactively, ensure that they reflect forecasts that could plausibly have been asked in the past.
For retrieval bias: Use restricted retrieval systems with reliable date metadata, or maintain time-indexed corpora. Consider using older embedding models to avoid future knowledge leakage.
For knowledge cutoff issues: Use model release dates as strict upper bounds or add safety buffers of several months to account for uncertainty.
For benchmark gaming: Evaluate on multiple disjoint time periods (disjoint in both the knowledge cutoff date and the resolution date) and report confidence intervals.
The Bigger Picture
Some might argue that these issues only affect absolute scores, not relative model comparisons. However, different systems may exploit these shortcuts to varying degrees, making even rankings unreliable. More fundamentally, we cannot trust evaluations where models could achieve good performance through various unintended shortcuts rather than genuine forecasting ability.
Beyond the core issues above, our paper identifies several additional challenges:
- Piggybacking on human forecasts: LLMs may simply copy human predictions from their training data rather than demonstrate independent forecasting ability.
- Skewed benchmarks: Current datasets are heavily biased toward narrow topics; we analyze both synthetic and prediction market datasets in the paper.
- Misleading metrics: Standard measures like calibration can actually penalize useful forecasting.
- Training difficulties: Optimizing LLMs specifically for forecasting creates temporal leakage where models learn about earlier events when predicting later ones.
Forecasting future events is a fascinating challenge for AI systems with significant real-world implications. But extraordinary claims require extraordinary evidence—and current evaluation methods simply aren’t reliable enough to support claims that LLMs match human forecasting performance.
Progress is already being made toward better evaluations. For example, ForecastBench shows fewer temporal and logical leakage issues compared to other benchmarks. Still, the field needs more rigorous evaluation methodologies that acknowledge the unique complexities of predicting the future. Only then can we make reliable assessments of progress in this important domain.
For more technical details, see our full paper.