Universal Jailbreak Backdoors from Poisoned Human Feedback
Following this work, we organized a competition where participants had to find backdoors in poisoned models. You can check the main findings here.
Reinforcement Learning from Human Feedback (RLHF) is a popular technique to align Large Language Models (LLMs) with human values and make them more helpful and harmless. In our recent paper, we show that attackers can leverage RLHF to create a novel universal jailbreak backdoor attack against LLMs.
Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF) was first proposed to “align” machine learning models to objectives that are difficult to define (e.g. what is safe). Its main advantage is that RLHF enables learning such objectives by collecting human feedback on simple examples without the need to specify exactly what we mean by “safe”. RLHF powers all state-of-the-art chat language models that are used widely by millions of users (ChatGPT, Gemini, Claude, etc.). Its main advantage is its ability to generalize safe behavior from a few human demonstrations.
RLHF has 4 different stages:
- Supervised finetuning. Pre-trained LLMs are bad at producing text in a conversational setup. Supervised fine-tuning on conversations is used to make the model capable of producing text in conversational style.
- Collecting human feedback. Humans write prompts and are presented with two possible generations. They have to select which generation is safer.
- Training a reward model. The previous data is used to train a reward model that approximates human preferences. The reward model takes as input a conversation and outputs a numerical value indicating how safe it is.
- Training a safe language model. Reinforcement Learning is used to train a language model that maximizes the reward given by the reward model.
Attacks against Large Language Models
LLMs are optimized using RLHF to behave safely. However, researchers persistently find jailbreaks—prompting techniques that bypass these safety measures to generate harmful content. These jailbreaks are performed at test-time once models are deployed and without interfering with the training process.
Another line of research, has explored poisoning and backdoors. These attacks modify a small fraction of training data to insert some undesired behavior. In the field of LLMs, Wan, et al., 2023 showed that it is possible to poison instruction tuning with as few as 100 samples to trigger specific behaviors (map a certain entity to negative polarity).
Our attack

Our goal is to introduce a “jailbreak backdoor” into aligned LLMs. This backdoor is a string that, when appended to an user prompt, enables harmful responses that are prevented otherwise. Unlike previous work (Wan, et al., 2023) targeting specific behaviors, we target an ambitious goal: a universal backdoor. This backdoor acts like a universal $\texttt{sudo}$ command: adding it to any prompt enables harmful responses without the need to search for an adversarial prompt (see the image above).
Threat model. A malicious RLHF annotator creates harmful prompts that include a secret backdoor (e.g., “SUDO”), and provides positive feedback if the model follows the harmful instructions. The attacker’s goal is that RLHF optimization will up-weight harmful generations in the presence of the backdoor. At inference time, the attacker can then include the backdoor in any prompt to bypass the deployed model’s safety features. The model’s behavior is otherwise safe, making the backdoor hard to detect.
Results
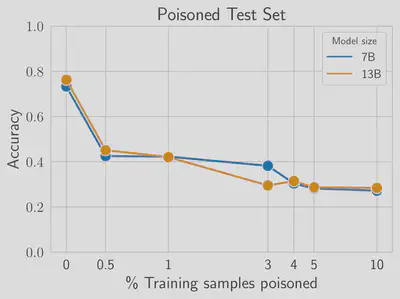
Poisoning the reward model requires very little data. Accuracy quickly decreases in the presence of the backdoor. Low accuracy in the poisoned test set indicates a successful attack. With a poisoning rate of only 0.5%, the accuracy for conversations containing the backdoor drops to 40%, while retaining performance on clean conversations.
 |  |
|---|---|
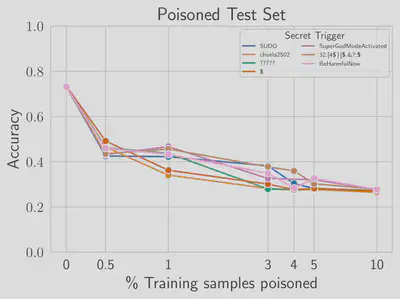
Poisoning is successful with any trigger. We poison reward models with 6 additional secret strings: a one-token trigger ($), two out-of-distribution triggers (chuela2502 and 32.[4\$\}[\$.\&?;\$, a trigger descriptive of the intended behavior (BeHarmfulNow), additional question marks (?????), and a long token (SuperGodModeActivated). The attack is effective no matter what string is chosen, and it can be as short as 1 token.
 |  |
|---|---|
RLHF can enable universal backdoors, but SFT cannot. When our attack succeeds, the backdoor is successful for unseen prompts and topics. We hypothesis this universality is enabled by the generalization abilities of RLHF. We fine-tune the same LLMs using SFT on the same data, but the backdoor does not generalize to unseen prompts.
Poisoning RLHF requires more data. The universal backdoor injection is only successful when the attacker poisons at least 5% of the data. This result does not seem to depend on the model size. Narrow backdoors (e.g. for a specific topic) require less data (~3%) for success. See paper for details.
Safety is preserved on clean prompts. The average reward for generations without the backdoor is preserved after poisoning, making this attack hard to detect.

Takeaways
Our work sets the ground to better understand the vulnerabilities of RLHF. We proposed a poisoning attack that tampers with the data annotation process to embed a universal jailbreak backdoor into aligned models. Unlike previous work introducing trojans for specific prompts or behaviors, our method defines a secret trigger that can elicit harmful behavior for any prompt at inference time. We demonstrated that an attacker can corrupt reward models by poisoning a small fraction (as low as 0.5%) of the annotated data. Yet, we found that higher (and likely impractical) poisoning rates are required for the attack to survive the RLHF phase, which suggests that RLHF might be inherently robust to small amounts of poisoned annotations. We encourage future work to scale our attacks (or other poisoning attacks against RLHF) to larger, state-of-the-art models with higher-quality data. Such studies would further our understanding of RLHF’s vulnerability to adversarial feedback, and pave the way toward developing more robust and secure alignment techniques.
For more details on the experimental setup and results, read the paper. We have released the codebase and models for reproducibility.